
Search Engineering Tech Talk 2024 Spring #searchtechjp
https://search-tech.connpass.com/event/318126/
RAG改善からみたクエリ・ドキュメント理解とリランキング(FRAIM株式会社 水野多加雄 さん)
- 適切なドキュメントが根拠の上位にこない
- 同じキーワードが含まれる関係のないドキュメントがランクイン
- ユーザのクエリ意図に合った回答ができていない
- 用語定義を聞いているのに、関連のオペーレーション方法をかえしてしまう
の課題にたいして、どう改善するコトについての話
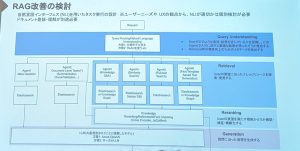

- SetFit
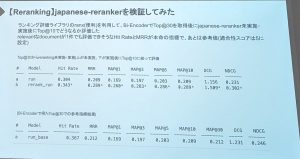
- Reranking
- japanese-reranker Cross-Encoder ベースモデルを日本語データセットJSQuAD等を用いて学習したもの
自然言語処理シリーズ-2 質問応答システム
質問応答タスクの分析が詰め込まれている。RAG改善のヒントになれそう
https://www.coronasha.co.jp/np/isbn/9784339027525/
文書登録時のチャンク、メタデータでドキュメントを絞り混むことが大事になる。
MongoDB Atlas Search, Vectorsearchの紹介、デモ (MongoDB Singapore 林田千瑛 さん)
MongoDB Atlas Searchの特徴の説明がありました。
データベース、検索エンジンが分離されていると、同じデータだけどOLTPと検索を二重持ちデータ同期も複雑。パイプラインの開発も必要
レイテンシー劣化も起こる
MongoDB は、3つのシステムを1つに集約データの同期も必要ない
セキュリティも安全
MongoDBトは別にAtlas ノードがある
インデックス更新も同時にされり
20240320 MLOps勉強会 v39
https://www.youtube.com/live/x24JCS-XLGU?si=Bs7IgxIPcZiHeB-X&t=584
検索失敗率のモニタリングから改善まで (株式会社ユーザベース 崔 井源 さん)
検索しても記事や動画を開かず離脱したものを検索失敗している
ここをモニタリング
プッシュ通知の文言で検索して失敗
既存は公開日順なので古い記事はなかなかでない
検索キーワードとして登録
通知されたコンテンツをアプリでみつけるのが難しいので検索ホーム
ラインキングロジックを改善
公開してからの経過日数、人気度合いをバランス良く考慮
重みを元に
Elasticsearchでトークンのオフセットがズレるバグについて (株式会社LegalOn Technologies 神田 峻介 さん)
Lucene.Elasticserach Character Filer
ユニコード正規化するとトークンのオフセットに不正の値が入るバグ
頻繁におきるものではない
Doc Character Filter TokenizerToken Filterで登録される
ユニコード正規化、形態素解析、ストップワード除去など
start_offsert
end_offset
平成が人文字の一個のunicodeとして
空文字列として認識してしまう
CharFilter offsets correction is wonky https://issues.apache.org/jira/browse/LUCENE-6595
対象外にしても、0.12%と検索結果への影響は少なそう
char_filter
unicode_set_filter https://www.elastic.co/guide/en/elasticsearch/plugins/current/analysis-icu-normalization.html