AWS LambdaライクなEvent Driven なサービスがGoogle Cloud Platformにも、以前書きましたが、
Google Cloud Functionsが使えるようになりましたので、レポートします。
まずは、プログラムコードをアップロードするGCSバケットを作成しておきます。
$ gsutil mb gs://BUCKET/
$ mkdir helloworld; cd helloworld
まずは、お約束なhelloworldから
$ vi index.js
exports.helloworld = function (context, data) {
context.success('Hello World!');
};
次に、コードのデプロイ。実行トリガーとして、HTTPトリガーを指定しています。HTTPトリガーはAWS API Gatewayに近い。
ただし、HTTP POSTのみ対応しており、GETは現状未対応になります。
トリガーとして、GCS、Google Pub/Subがそのほかに対応しています。
Cron トリガーについては、テスター用のGoogle Groupで今後対応しそうなdiscussionがありました。
Cron triggering for Cloud Functions is on our radar.
$ gcloud alpha functions deploy helloworld --bucket BUCKET --trigger-http Copying file:///tmp/tmpjPc7fq/fun.zip [Content-Type=application/zip]... Uploading ...g-deploy/us-centra l1-helloworld-mtlxhowupkjw.zip: 193 B/193 B Waiting for operation to finish...done. entryPoint: helloworld gcsUrl: gs://BUCKET/us-central1-helloworld-mtlxhowupkjw.zip latestOperation: operation-adc6aebf-e0d9-471e-92fb-8cdf865fc206 name: projects/PROJECT_ID/regions/us-central1/functions/helloworld status: READY triggers: - webTrigger: url: https://us-central1.PROJECTID.cloudfunctions.net/helloworld
初回のデプロイは、GKE Clusterを作成する(クラスタ数2)ので、多少時間がかかります。
$ curl -X POST https://us-central1.PROJECTID.cloudfunctions.net/helloworld Hello World!
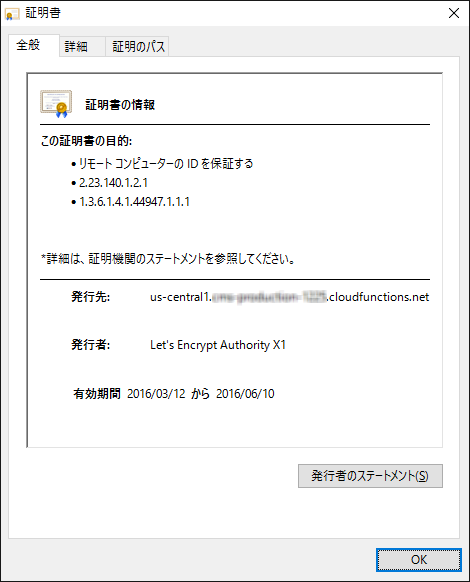
Cloud Function用のSSL証明書として、Let’s Encrypt Authority X1が使われていることを確認。
実行ログを確認すると、functionsコールは1 ms。
$ gcloud alpha functions get-logs helloworld LEVEL NAME EXECUTION_ID TIME_UTC LOG D helloworld - 2016-03-12 00:36:54.512 User function helloworld loaded D helloworld OLsMt0WnTFFG-0 2016-03-12 00:38:20.796 User function triggered, starting execution D helloworld OLsMt0WnTFFG-0 2016-03-12 00:38:20.797 Execution took 1 ms, user function completed successfully
最後に、Cloud Founctionsの削除。
$ gcloud alpha functions delete helloworld Resource [projects/PROJECTID/regions/us-central1/functions/h elloworld] will be deleted. Do you want to continue (Y/n)? y Waiting for operation to finish...done. Deleted [projects/PROJECTID/regions/us-central1/functions/helloworld].
Google Cloud Functions削除してもGKE cluterが削除されません。GKEクラスタはn1-standard-1(クラスタのタイプは変えられない?)。
GKE Clusterを頻度に削除すると、週5の証明書の制限に抵触して接続が行えなくなることがあります。
I inspected your logs – we are not really supporting a model in which you would remove clusters that often
(after every deployment).
That is why you got issues with HTTPS (hitting limit on number certificates,
currently 5 per week for whole project). HTTP (without S) endpoint should be fine.
The workaround would be not to remove clusters after each “test” – instead let them run –
you should get a coupon from us to finance it for a while.
実行環境のDebianの実行コマンドをnode.jsから実行させることもむろん可能です。
$ vi index.js
var exec = require('child_process').exec;
exports.sampletest = function ( context,data) {
child = exec(data.cmd, function (error) {
context.done(error, 'Process complete!');
});
child.stdout.on('data', console.log);
child.stdout.on('data', console.error);
};
$ gcloud alpha functions deploy sampletest --bucket cms-stg-deploy --trigger-http
$ curl -X POST https://us-central1.PROJECTID.cloudfunctions.net/sampletest --data '{"cmd":"cat /etc/debian_version"}'
$ gcloud alpha functions get-logs sampletest nRrOVegpcqrn-0 2016-03-12 01:11:34.008 7.9
Cloud Functionsの実行環境としてはDebian 7.9が使われていますことがわかります。BigQuery、DataStoreとの連携も可能かと。BackendでVMインスタンスが利用されていますが、インスタンスの管理が低減できる。
現在以下Execution Failureがあるようです。
- リトライの保証はないが、60秒間隔で2回行われること
- 最大実行時間60秒(デフォルトでデプロイ時に変更可能)
- Functionsが無限ループを起こす場合、ブロックされる。