2016年3月27日
から hiruta
Google Cloud FounctionsからBigQueryへのアクセス #gcpja #gcpug はコメントを受け付けていません
Google Cloud Founctionsからgcloudのnode.js moduleでbigqueryにアクセスをしてみました。
が、デプロイ失敗。
$ gcloud alpha functions deploy bigquerytest --bucket XXXXX-deploy --trigger-http
Copying file:///tmp/tmp6OEBwr/fun.zip [Content-Type=application/zip]...
Uploading ...deploy/us-central1-bigquerytest-zyupwaipvuxb.zip: 16 MiB/16 MiB
Waiting for operation to finish...failed.
ERROR: (gcloud.alpha.functions.deploy) OperationError: code=13, message=Error during function code deployment: User function failed to load: Code in file index.js can't be parsed. Please check whether syntax is correct.
Detailed stack trace: Error: Module version mismatch. Expected 14, got 46.
at Error (native)
at Module.load (module.js:355:32)
at Function.Module._load (module.js:310:12)
at Module.require (module.js:365:17)
at require (module.js:384:17)
at Object.<anonymous> (/user_code/node_modules/gcloud/node_modules/grpc/src/node/src/grpc_extension.js:38:15)
at Module._compile (module.js:460:26)
at Object.Module._extensions..js (module.js:478:10)
at Module.load (module.js:355:32)
at Function.Module._load (module.js:310:12)
モジュールバージョンが合っていないエラーのようだ。
Alphaテスター用google group(cloud-functions-trusted-testers)だと、同じ症状が起きている方の回答を見ると、0.12.7で動くとのこと。
I’ve changed the version of node.js gcloud dependency to 0.28.0 and it has fixed the problem.
What version of node.js are you using ? The function runs under node.js in version 0.12.7.
Ubuntu 14.10には下記node.jsのバージョンがインストールされている。新しめのが入っていた。
hiruta@ubuntu:~$ node -v
v4.4.0
hiruta@ubuntu:~$ npm -v
2.14.20
該当するnode.jsをダウンロードして試してみました。
$ wget https://nodejs.org/download/release/v0.12.7/node-v0.12.7-linux-x64.tar.gz
パッケージjsonも作成。
$ cat package.json
{
"name": "bigquerytest",
"version": "1.0.0",
"description": "",
"main": "index.js",
"dependencies": {
"gcloud": "^0.28.0"
},
"devDependencies": {},
"scripts": {
"test": "npm test"
}
}
npm install gcloud --save
vi index.js
var gcloud = require('gcloud')({
projectId: '<PROJECT ID>'
});
exports.bigquerytest = function (context, data){
var bigquery = gcloud.bigquery();
var query = 'SELECT url FROM [bigquery-public-data:samples.github_nested] LIMIT 20';
bigquery.query(query, function(err, rows, nextQuery) {
if (err) {
console.log('err::', err);
}
console.log(rows);
if (nextQuery) {
bigquery.query(nextQuery, function(err, rows, nextQuery) {});
}
console.log(rows);
});
context.success();
};
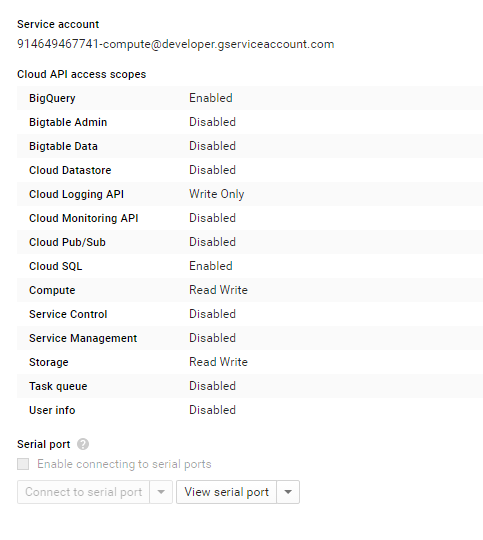
credentialsは別段指定する必要がない。Backendのインスタンス(alpha版の場合、GKE)でCloud APIへのアクセスが許可されているため。
ただし、projectIdの記載は必要です。
$ gcloud alpha functions deploy bigquerytest --bucket XXXXX-deploy --trigger-http
デプロイが成功したら、Functions用のHTTP(S) Endpointsにアクセスしてみます。
$ curl -X POST <Functions用のEndPoinit>
ログに、BigQueryから情報が取得できています。
$ gcloud alpha functions get-logs
また、GCSにnginx等のアクセスログを退避して、Cloud FounctionsでBigQueryにinsertするユースケースにも使えると思われます。