2016年12月9日
から hiruta
Google Cloud Functions で環境変数を使うには(Tipsネタも) #gcpug はコメントを受け付けていません
Google Cloud Platform(1) Advent Calender 12/10分で書きました。
Runtime Configurationsはまだα版なので、今後仕様が変わる可能性があるかもしれません。
AWS Lambda、Azure Functionsとかでは、環境変数を扱えるので、Google Cloud Functionsでも使いたい願望が。
現状、Google Cloud functionsで環境変数を扱うことはできない。
ただ、Google Cloud FunctionsのEarly Access用Google Groupに環境変数を対応する予定があるか、聞いたところ、現状Runtime Configuration FundamentalsでGoogle Cloud Client libraryでは、対応しておらず、low-level APIのRuntime Configurationで行う必要がる。(Google Cloud Client libraryで対応してほしい。)
Runtime Configurationが対応しているGoogle APIはv1、v2には対応していないので注意。
https://cloud.google.com/deployment-manager/runtime-configurator/
Runtime Configの作成
gcloud alpha deployment-manager runtime-configs create functions-prod
gcloud alpha deployment-manager runtime-configs variables set TEST-KEY abcd1234efgh5678 --config-name functions-prod
function auth (callback) {
var google = require('googleapis');
google.auth.getApplicationDefault(function (err, authClient) {
if (err) {
callback(err);
return;
}
if (authClient.createScopedRequired && authClient.createScopedRequired()) {
authClient = authClient.createScoped([
'https://www.googleapis.com/auth/cloud-platform',
'https://www.googleapis.com/auth/cloudruntimeconfig'
]);
}
callback(null, authClient);
});
}
function getVariable(configName, variableName, callback) {
var google = require('googleapis');
var config = google.runtimeconfig('v1beta1');
var fullyQualifiedName = 'projects/' + process.env.GCLOUD_PROJECT +
'/configs/' + configName +
'/variables/' + variableName;
auth(function(err, authClient) {
config.projects.configs.variables.get({
auth: authClient,
name: fullyQualifiedName
}, function(err, variable) {
if (err) {
callback(err);
return;
}
// decode the value as values are saved as base64-encoded strings
callback(null, Buffer.from(variable.value, 'base64').toString());
});
});
}
exports.myFunction = function (req, res) {
getVariable('functions-prod', 'TEST-KEY', function(err, stripeKey) {
// do something involving "stripeKey"
res.send('OK');
});
};
GoogleAPIs Node.js clientは8.0.0で確認。
また、Functionsでエラーになった場合、ErrorReportingと連携できるようになっています。
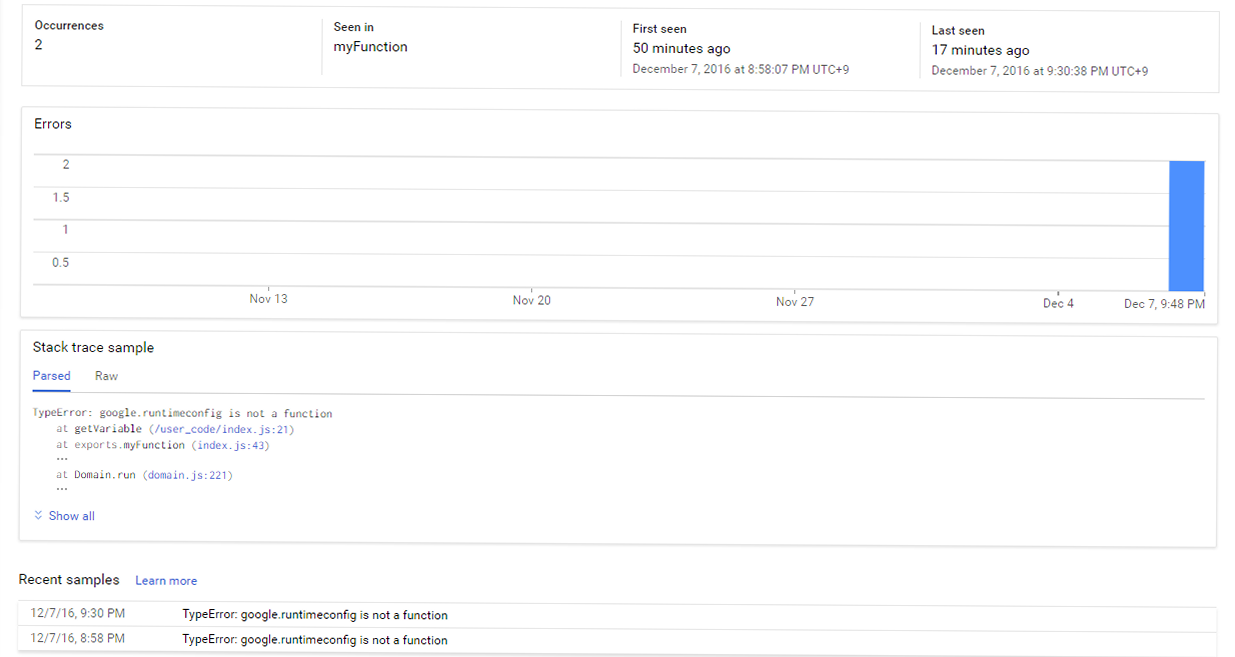
functions.env 変数でRuntime Configの環境変数を取れるようになるらしい。
As an FYI for anyone using the Firebase tools for Cloud Functions, the functions.env variable is built using Runtime Config as well.
Tipsネタをいくつか。
GCSトリガーでfunctionsを実行する際、lacks permissionとか発生するケースが。
edit object default permission でcloud functions用Service Account (Service Account名はCloud functionからBigQueryに登録した際にエラーメッセージの中から見つけました)を登録することで解決。以前はこの設定なくてもうまくいっていたんだけど。
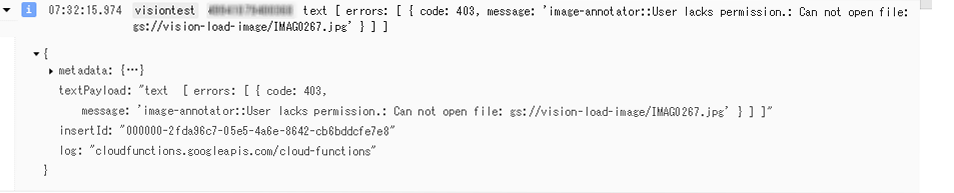
Google Cloud Clinent library for node.jsのバージョンによって、発生しました。発生したバージョンは、0.35.0。Google Cloud Client library は、0.44もでているようだが、使えないバージョンもあるので、注意が要。動作がOKだったバージョンは、0.28.0でした。
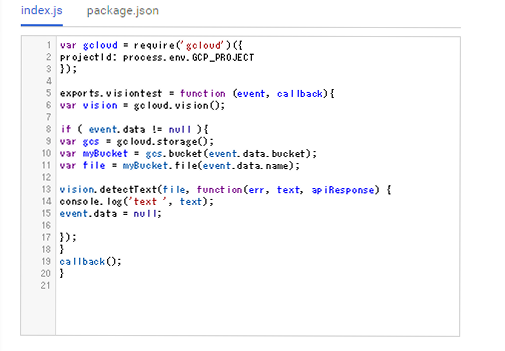
12/9 の0:00ごろ?WEB Consoleでcloud functionsのインライン編集に対応していました。新規でfunctionsを作成すると、現仕様のサンプルコードが自動生成されます。下記はCloud Vision APIでLabel Detectionを使う例になります。package.jsonの編集にも対応していて、便利です。