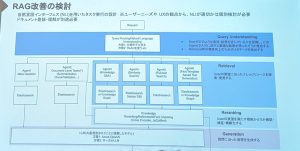
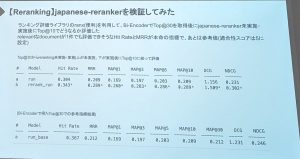
地方のCloud native daysへの参加は、Cloud native days Fukuokaに続けて、2イベント目でした。
キーノートセッションから
クラウドネイティブな省エネサービスの内製開発で、BizDevOpsを実現する
https://event.cloudnativedays.jp/cnds2024/talks/2333
Sierに発注すると画面の修正とかも高くなるので内製開発をスタート。
兼業なので人少ないなかでのスタートで苦労話も
Codespacesもそうだけど、ローカル環境だとミドルウェアのバージョンとかMac、Windowsで
変わってしまうが、CodeCatalyst Dev Environemtだと環境共通化できて開発環境構築も楽になる
リードタイム、コストを最適化しながら回復性を求めるクラウドネイティブ戦略
https://event.cloudnativedays.jp/cnds2024/talks/2334
サーバーレスを主としたアーキテクチャ
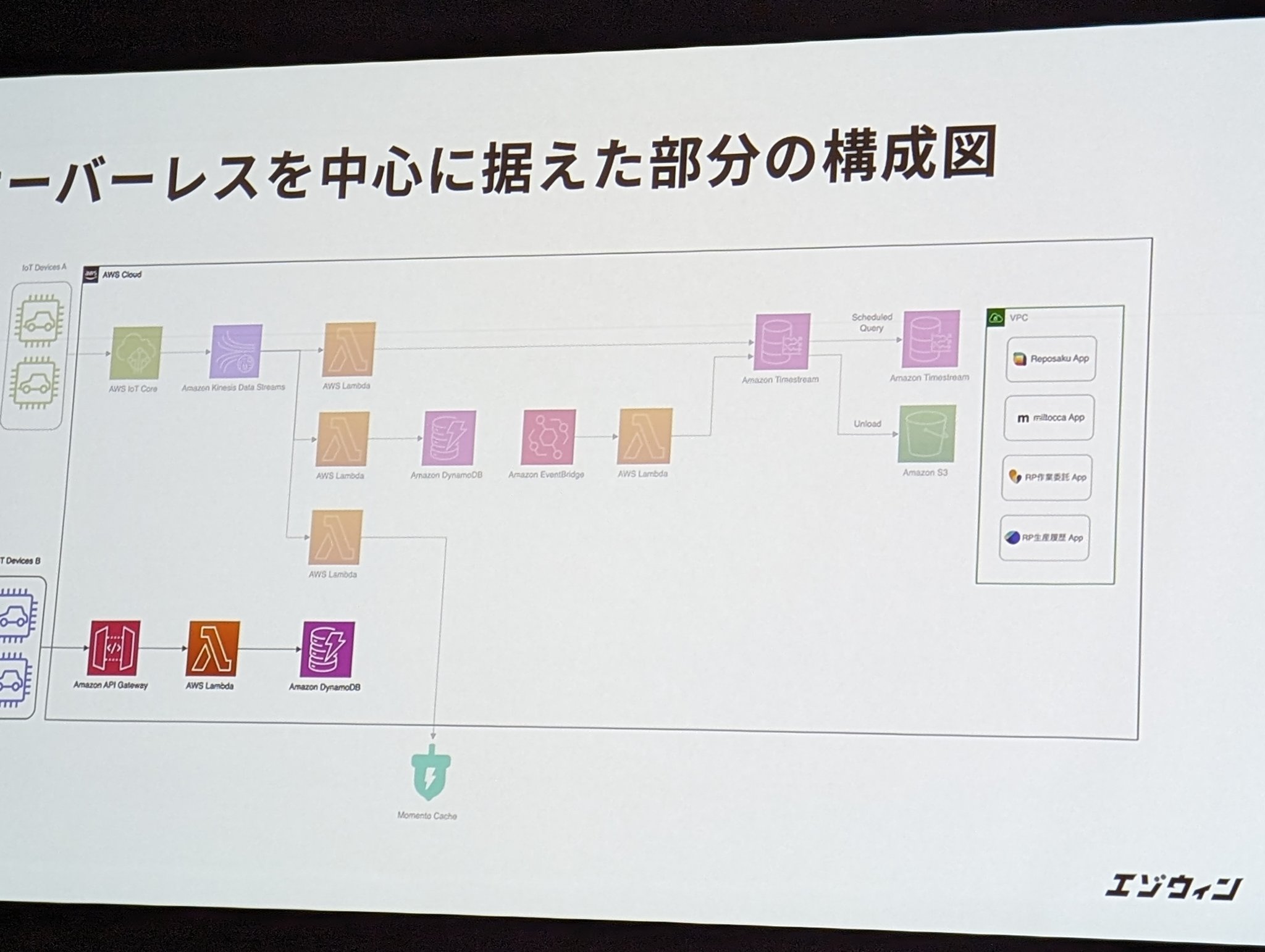
タイムアウト設定が、フロント(API Gateway) <バック(Lambda)の場合、API Gatewayがタイムアウトされても、バックは処理し続けるが、すでにクライアントには50xで返されると不整合がおきるケース

次世代のクラウドネイティブ基盤、Wasmの今と未来
https://event.cloudnativedays.jp/cnds2024/talks/2330
WASMはポータビリティ、Sandboxで動かせる、軽量
jit
https://github.com/wingo/wasm-jit
The AoT Compiler
https://wasmedge.org/docs/start/build-and-run/aot/
WASMはStack machine
Linear Memory
https://wasmbyexample.dev/examples/webassembly-linear-memory/webassembly-linear-memory.rust.en-us
WebAssembly System Interface (WASI)
https://wasi.dev/
wasi-nn もローカルLLMをWASMで動かすことも。
runwasi
https://github.com/containerd/runwasi
jco
https://github.com/bytecodealliance/jco
スポンサーキーノート
エンドツーエンドの可視性を実現するクエスト
https://event.cloudnativedays.jp/cnds2024/talks/2331
インフラモニタリングからRUMのモニタリングまでDatadogで提供している。
state of Cloud Cost
https://www.datadoghq.com/state-of-cloud-costs/
成長し続けるTVerサービスを支えるオブザーバビリティとカスタマーサポート
https://event.cloudnativedays.jp/cnds2024/talks/2338
デプロイ記録をnewrelicで管理
https://newrelic.com/jp/blog/how-to-relic/record-deployment-with-github-actions
デプロイ・QA・Four keys を自動化×見える化する freee の統合デリバリー基盤
https://event.cloudnativedays.jp/cnds2024/talks/2281
開発者体験を向上する
デプロイ禁止日のGoogleカレンダーとの連携で禁止日はできないようなことも
ロールバックできるできないことも
Four keys
https://cloud.google.com/blog/ja/products/gcp/using-the-four-keys-to-measure-your-devops-performance
デプロイのなかにPRが多いとコードの変更もその分含まれるので、不具合起きるケースもありそうかな
Service Weaver で始めるモジュラー モノリス、そしてマイクロサービスへ
https://event.cloudnativedays.jp/cnds2024/talks/2332
Service weaver、モジュール化されたモノリスとして記述してもマイクロサービスとしてデプロイできる
Introducing Service Weaver: A Framework for Writing Distributed Applications
https://opensource.googleblog.com/2023/03/introducing-service-weaver-framework-for-writing-distributed-applications.html
Legacy開発はモジュール間で問題おきないか慎重にならざるをえない。
マイクロサービスでも苦悩がある。

Service Weaverのコアライブラリ、モジューラーなものを別のプロセスに動かせるようにジュネレートしてくれるのか
単一バイナリだけどルーティングなり分散環境にデプロイをよしなにしてくれる
k8s deploymentやserviceの生成もしてくれる。
Service weaverのTracingはOpenTelmetryに依存している
テレメトリーシグナルの相関、してますか?第一原理からのデバッグを支える計装
https://event.cloudnativedays.jp/cnds2024/talks/2243

DB接続エラー、リクエスト量、コネクションなど他の情報があるようにしたい。
第一原理からデバッグできる
テレメトリごとの連携が重要
テレメトリーシグナルの相関は、ログのなかにトレースIDを入れるとか
ログをもとにメトリクスを作るとか、タイムスタンプと量でメトリクスにするとか
Google CloudのGKE logging、構造化ログになっているので、ログからメトリクスへの連携もしやすい
クラウドネイティブにおけるセキュアなソフトウェア・サプライ・チェーンの考え方とベストプラクティス
https://event.cloudnativedays.jp/cnds2024/talks/2336
ソース、ビルド、リポジトリのフェーズで侵害される可能性があるので、Software Supply Shainの対象になる。
クラウドネイティブにおける脅威ポイント
Source Code Theats
Build Theats
Dependency Theats
Deployment Theats
オープンソースに信頼されていないものが含んでいないか
最近だとxzの件もありましたし。
変化と挑戦:NoSQLとNewSQL、Serverless Databaseの技術革新とマルチテナンシーの秘密
https://event.cloudnativedays.jp/cnds2024/talks/2249
DynamoDBもamazonのトラフィック裁くのに作られたDynamoをベースにしている
Cloud SpannerももとはGmailとかつかわれていたSpannerをベースに誕生している
水平スケーリングに強いSQL NoSQL
リレーショナルではない。KVでテーブル設定していく
https://qiita.com/yoshii0110/items/bd71b4479ee71aa6bf53
https://zenn.dev/koiping/articles/76f12a3567da53
Discussion board
Discussion board企画でもこまっていることを議論などされていました。


次回
Cloud Native Days Winter 2024
2024/11/28,29
東京(有明セントラルタワー&カンファレンス)
8/27 KubeDay Japanと同じ会場です。
https://events.linuxfoundation.org/kubeday-japan/
ステンレスキューブを再度にもらいました。