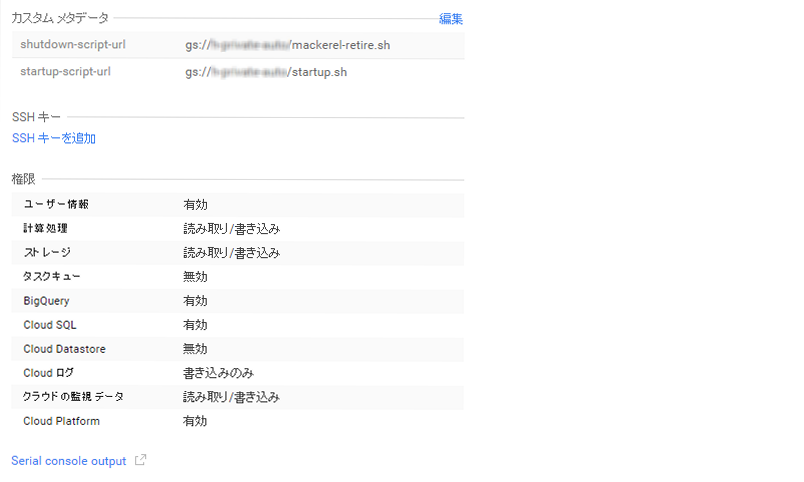
本日のGCPUG in Fukuoka 1st でした。(初福岡でもありましたけど)
「Google BigQueryとCloud Dataflowでかんたんビッグデータ分析」Google デベロッパーアドボケイト 佐藤 一憲氏 @kazunori_279
google検索のためのソフトウェア開発を10年ほどやってきた
市販のDBではまかないきれない
ベストなファイルシステムを作っていこう
GFS、MapReduce
1億人のアクセスログをjoinするとか、普通のDBだと止まる
けど、MapReduceは処理できてしまう
ものすごい規模で展開されている
Google 検索のインデックス規模は100PBを超えている
BigDataとの戦い
ログも何十TB
Adword 広告のサービス
APIのログを取ってみても、何TBになる
内部的には、Dremelのテクノロジ
Dremelのテクノロジを外のお客様に公開 = BigQuery
BigQueryについて
hadoop、MapReduce
百台のマシンにばらばらにして、データの整列とか並列に
安いサーバーでも並列で何百台で処理
簡単に使える。普通のSQLで
非エンジニアでの利用が多い。Google社内では。
他のユーザへの影響もない。
パフォーマンスも圧倒的に多い
デモ サンプル wiki10B wikiのデータを100億行のデータが入っている
タイトルに、「あいうえお」正規表現で実行
3s キャッシュオフでも
Storageのコストと検索のコスト
BigQueryは、S3より安い。ログをBigQueryに入れる案件も
アウトプットにGoogle スプレットシートで分析もできる。
Hadoop の解析結果をHBaseに入れる必要がある
Hadoopのプログラムテーブルに対して処理することができる
BIツール「BIME」について
BigQueryはあらかじめインデックスを作っておく必要がない
なんで速いのか
データ分析用のデータベース
行の更新はできない
行の追加のみ
ログ
カラム単位で違うディスクに入れておくカラムベースストレージ
スコアだけ集計したいとき、ストアデータだけ読んできて解析
何千台のサーバーを自由で使える
Googleのサーバーは用途で分けていない
他のクラウドベンダーではありえないこと
全てのサーバーはGoogleのサービスに共有できる
Google検索の仕組みをそのまま使ったのがBigQuery
他社のクラウドベンダーには難しいのでは
100億行のデータ + join + 10億行でhadoopでやろうとすると数十分
BigQueryだと、3min
Fluendとの組み合わせが便利
Dataflow
Dataflowは現在は、α版。ただβも近いうちにリリースされるとのこと。
BigQueryにデータをインポートする必要がある
データによっては、クレンジングが必要なデータもある
ETL データをリードして、不要なデータをはずすとか
Flume MapReduceの上で動くフレームワーク
MapReduce
処理が多段に。
多段の処理を組み立てるのがめんどくさい
データのパイプラインをプログラムコードで書く。MapReduceで自動生成 →Flume
何台くらいで動かすのか最適化も自動でやってくれる
最適な台数を見つけるのに、MapReduceを何台か回す →Flumeが勝手にやってくれる
MilWheel ストリーム処理
広告基盤でリアルタイム処理する必要。インプレッションとか
リアルタイム集計したい
flume、MilWhelをベースに作り直したのがDataflow
Full Managementで提供すたのがDataflow
バッチ処理、ストリーミング処理も。複数のDBを統合も
関数プログラミングで
バッチとストリーム処理両方に適用
運用コストも掛からない
SDKもオープンソース
実装を変えることもできる
GroupByKey
Sで始めるものとか実行できる
Fixed Windows 1hおき
Sliding ストリーミング
Direct Runner 手元で確かめる
Cloud Dataflow Service Runner
GCEインスタンス上で
Spark-dataflow
Dataflowを実装した例も
過去のデータがGCS
結果はBigQuery上で
ユーザがビデオ見て終わるのを3minごとにWindowで集計する例
Pipelineの定義
テキストデータのparse
カンマ区切りのデータをばらす
アーカイブに保存
BigQueryのデータのカラムに入れる
ランキングを集計
を並列に
裏でGCEのインスタンスが起動して処理する
起動する台数は、キモ細かく制御できる。
DataflowのアーキテクチャーはAsakusa Frameworkに近いとのこと。Kinesisにも近そうだが、違な点も。
「Firebaseによるリアルタイムモバイル開発」Google デベロッパーアドボケイト Ian Lewis氏 @IanMLewis
時代は、モバイルにシフト
モバイルを使っているユーザが多い
パソコンと両方使っている人も多いが、モバイルにシフト
モバイル対応を考えるときに課題も
マルチデバイス スマホ、タブレットそれぞれ iOS、Androidか多岐に渡っている
ソフトウェアも変わるので、開発も困難
これから、Wear、TV、自動車も
バックエンドサーバーも
初めての人が構築するのは難しい
モバイルは移動が前提なので、移動した場合にも対応も
そこで、Firebaseを使うとなぜ便利か
リアルタイムDB、ユーザ管理、ファイルホスティング
DBは、NoSQL
SQLを使わない。JSON
ミリ秒単位で更新
スマホ、Firebaseごとにデータを保持。それぞれsyncしている
データを保存するだけでsync
オフライン、ネットワークが不安定になっても、読み込んだりできて、接続したらsyncしてくれる
ユーザ管理も柔軟に
CDNも勝手にやってくれる
Npm install -g firebase-toolsでfirebase command line toolsを入れられる。(→ここ)
Firebase init セキュリティの設定とかかかれているjsonファイルが取得される
ファイルホスティング対象しないようにもできる
正規表現でマッチングすることもできる
Firebase deply アップロード
認証とオンライン状態
twiter側でアプリを作成。ClientIdを登録。認証用のCallbackでID、パスワードを入れて自分のアプリにリターン
ユーザがオンラインになったら、通知をしてくれる。モバイルの場合、ねっとわーくの状態が変わるので、この辺の設計が大変になるが、firebaseをネットワークの状態をみて、処理を書くことができる
課金プランは、コネクション数。
超えた場合は、アプリが動かなくなるのではなく、超えた分は課金される
Google docsのアプリのようなものを作るのは簡単
GCEハンズオンワークショップ 吉積情報 吉積礼敏氏
GCE + CloudSQLでwordpressを立ち上げるハンズオン。テキストは下記に公開されています。
goo.gl/ua5fQw
https://github.com/gcpug/gcp-demos
プロジェクトIDとプロジェクト名は同じにしておくといい。プロジェクトIDはGCP Commnad line toolsとかに利用するので。
ハンズオン形式なので、気になった点を2,3点
画面でもインスタンスを起動できるが、コマンドだと以下のようになります。
gcloud compute instances create handon-20150411-01 –machine-type n1-standard-1 –image “https://www.googleapis.com/compute/v1/projects/ubuntu-os-cloud/global/images/ubuntu-1404-trusty-v20150316” –network product-network –boot-disk-type “pd-ssd” –zone “asia-east1-a”
ハンズオン途中で、gcloud compute instances createでVMインスタンス作る際、特定zoneでエラーになった。
– The zone ‘projects/XXXXXX/zones/asia-east1-a’ does not have enough resources available to fulfill the request. Try a different zone, or try again later.
ただ、ホテルに戻った後、再トライしたところ、問題なかったので、まれにインスタンスが起動できないことがある(とのこと)。
CloudSQLインスタンスを画面から作成。※ここだけは、コマンドが確認できない
RDSのインスタンス生成より劇的に速い。
cloud sql instances create wp-demo –region asia-east1 –assign-ip –authorized-network 107.XXX.XXX.XXX
5.6系はベータなので、GA Releaseを。
VMインスタンスに元々Google Command Line Tools ( gcloud )が入っているが、ただバージョンが古いとかasia-east-1 zoneを認識しない問題があるようです。
Manage Cloud SQL Instances by Cloud SDK →https://cloud.google.com/sql/docs/cloud-sdk
CloudSQLもCLIでReadReplica作成、バックアップWindowの設定などできる。
ただ、CLIによるDBユーザ追加のコマンドの記載がない。ハンズオンでは画面からDBユーザ作成を行った。ユーザ制御のCLIコマンドを探してはいるが、現状見つけられていません。
最後に。
BigQuery、Dataflowと「Big-DataはGoogle」と言えるほど、Googleのインフラ基盤はすごいと再認識できた勉強会でした。
Carrier Interconnectは現在テスト中とのこと。近々利用できるようなことも