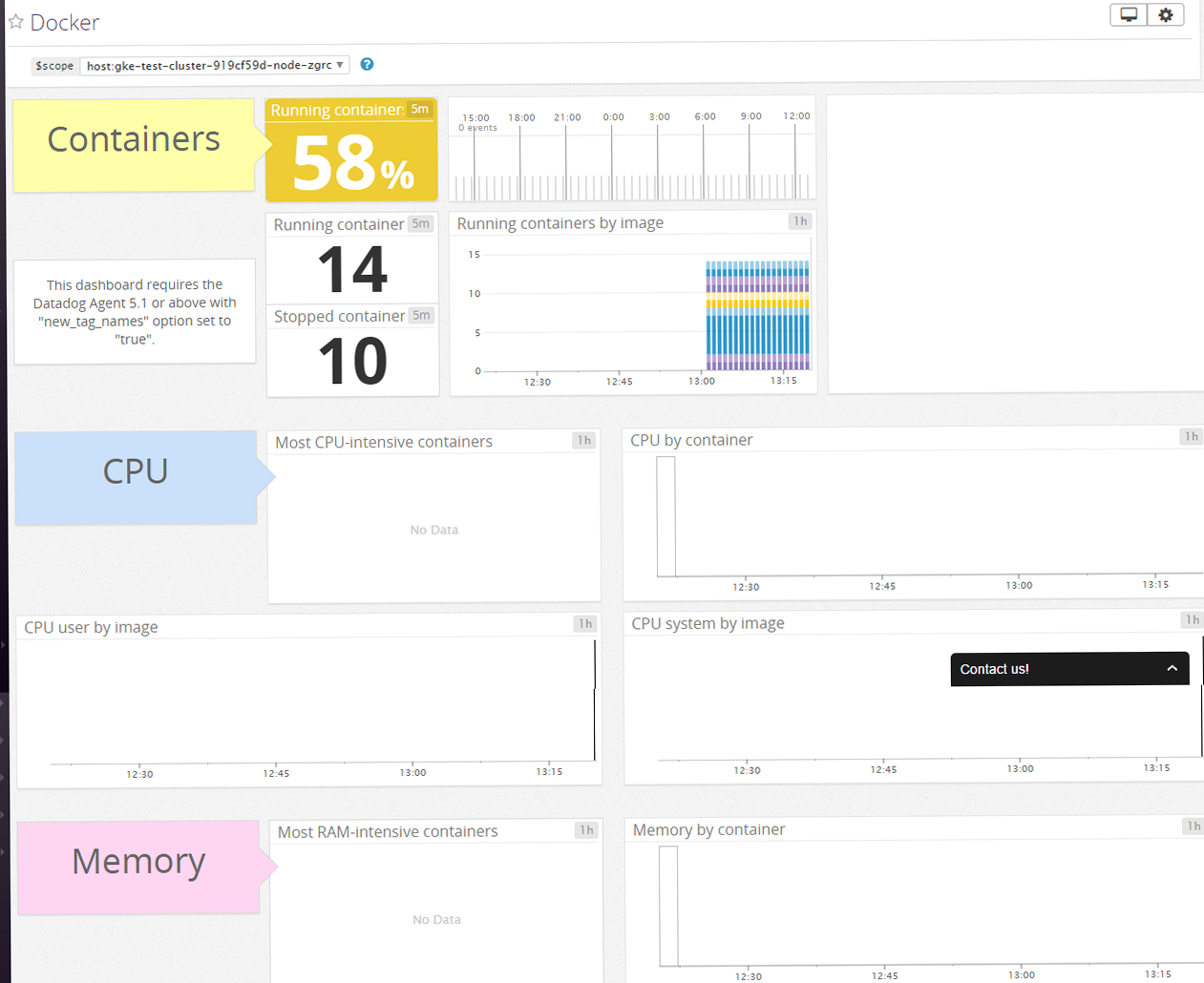
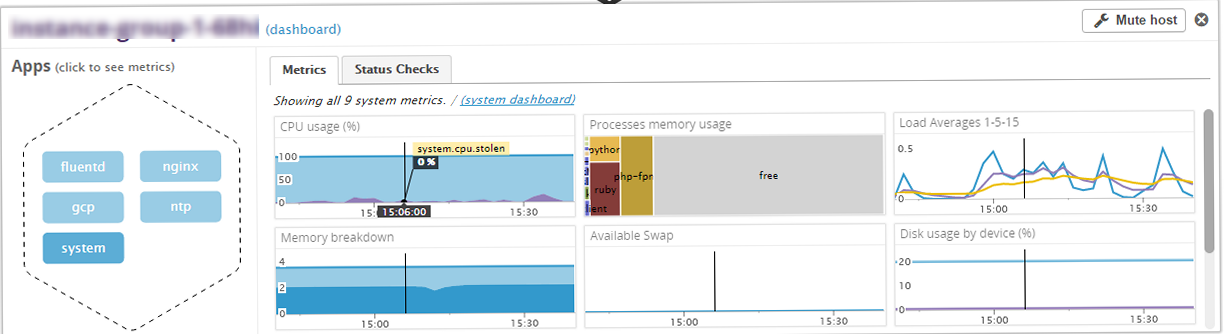
Datadogで、Fluentd、nginxについても監視が可能。
Nginxのモジュールngx_http_stub_statusが有効である必要があります。組み込まれているかどうかは、nginx -Vで確認が可能です。
/etc/nginx/conf.d/virtual.conf
location /nginx_status {
stub_status on;
access_log off;
}
datadogの設定ファイルを作成します。.exampleでサンプルがおいてあるので、コピーして作成すればstatus urlを変更すれば完了。
/etc/dd-agent/conf.d/nginx.yaml
init_config: instances: # For every instance, you need an `nginx_status_url` and can optionally # supply a list of tags. This plugin requires nginx to be compiled with # the nginx stub status module option, and activated with the correct # configuration stanza. On debian/ubuntu, this is included in the # `nginx-extras` package. For more details, see: # # http://docs.datadoghq.com/integrations/nginx/ # - nginx_status_url: http://localhost/nginx_status/
/etc/td-agent/td-agent.conf
<source> type monitor_agent bind 0.0.0.0 port 24220 </source> <match *> id plg1 type forward <server> host localhost </server> </match>
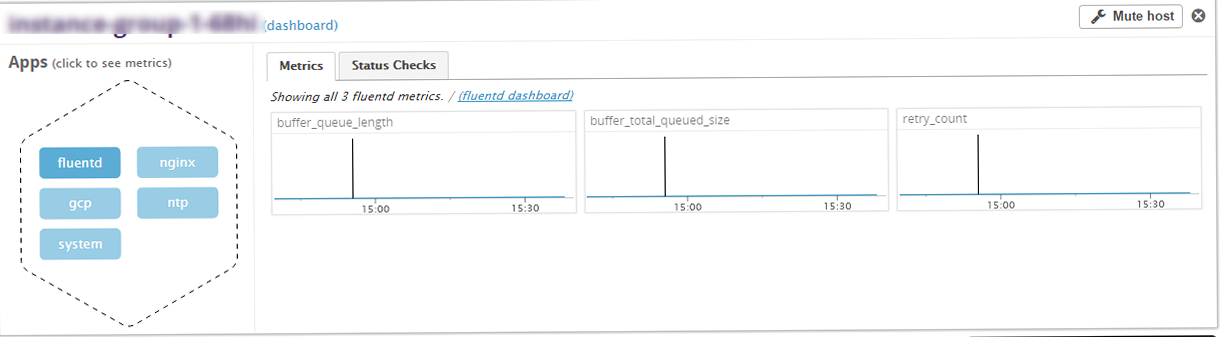
設定を反映するには、fluentdを再起動します。
systemctl restart td-agent
下記コマンドで取得できるようになれば設定が反映されています。
curl -s http://127.0.0.1:24220/api/plugins.json
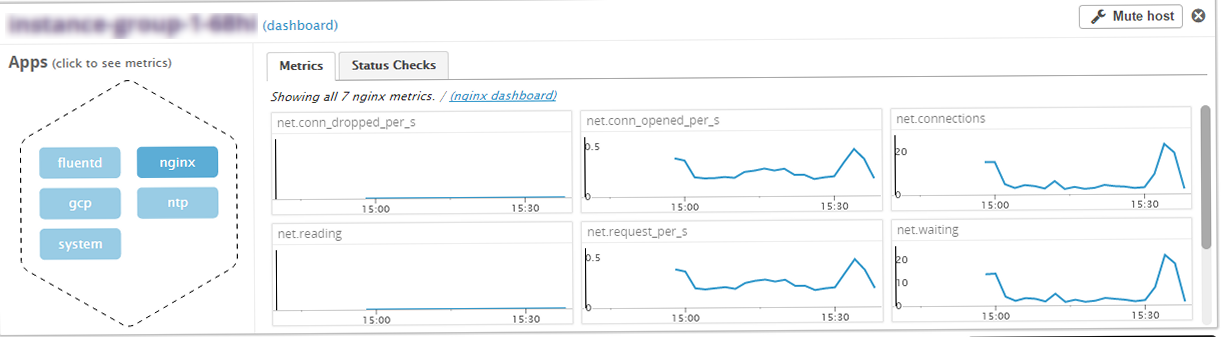
次に、datadogの設定ファイルを作成します。nginxと同様exampleからコピーでほぼ完了。
/etc/dd-agent/conf.d/fluentd.yaml
init_config: instances: # Every instance requires a `monitor_agent_url` # Optional, set `plugin_ids` to monitor a specific scope of plugins. - monitor_agent_url: http://localhost:24220/api/plugins.json plugin_ids: - plg1 # Optional, set 'tag_by' to specify how to tag metrics. By default, metrics are tagged with `plugin_id` #- monitor_agent_url: http://example.com:24220/api/plugins.json # tag_by: type
最後に、datadogのagentを再起動します。
sytemctl restart datadog-agent
設定が反映されているか下記コマンドで確認できます。
dd-agent info
fluentd ------- - instance #0 [OK] - Collected 3 metrics, 0 events & 2 service checks nginx ----- - instance #0 [OK] - Collected 7 metrics, 0 events & 2 service checks
それ以外にも、RabbitMQ、Cassandra、HA Proxy等監視できるプロダクトが豊富になっています。