2015年11月22日
から hiruta
先日のIoTハンズオンに参加しました。 #cmdevio はコメントを受け付けていません
先日AWSモバイル/IoTサービス徹底攻略!!~Developers.IO Meetup番外編~に参加しました。
センサーからOpenBlock BX1 →SORACOM Air →AWS IoT→DynamoDBまで登録する流れをハンズオンで体験できました。
- SIMの挿入取り出しがしずらい。OpenBlock BX1ではナノサイズではなく、フルサイズで
- OpenBlock BX1の時刻は同期しておかないとログ収集がうまくいかない
- root証明書等スペースがあるファイルだとAWS IoTの設定ができない
Raspberry Pi2 等でも同様な仕組みは作成できると思われるが、Open Block BX1は、AWS Mobile SDK/3Gモジュール/WebUIが組み込まれており、事前準備がかなり省けることが実感。
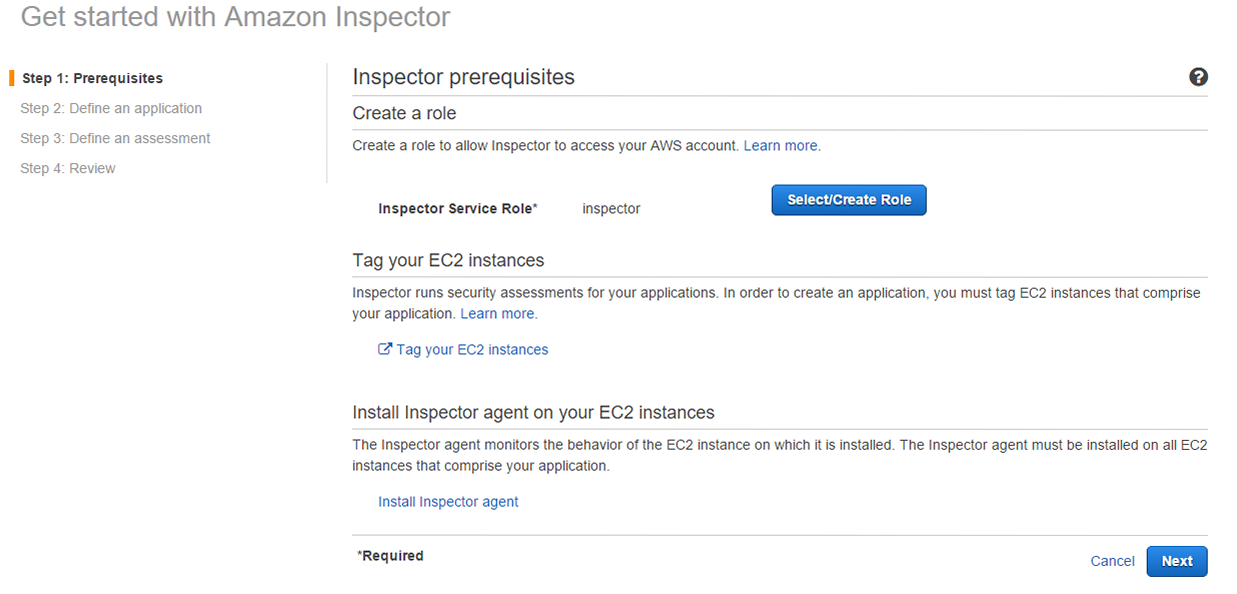
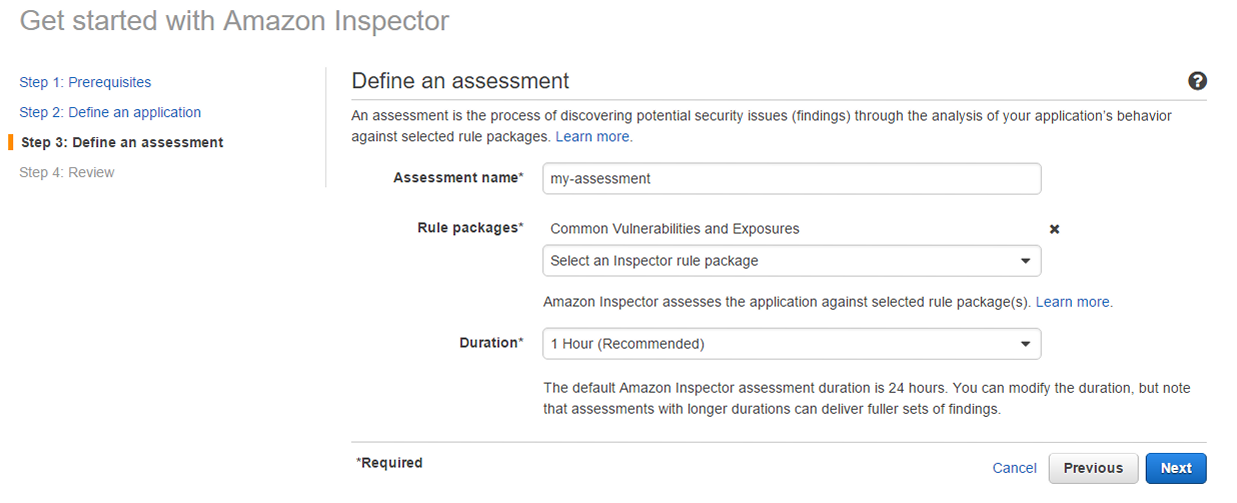
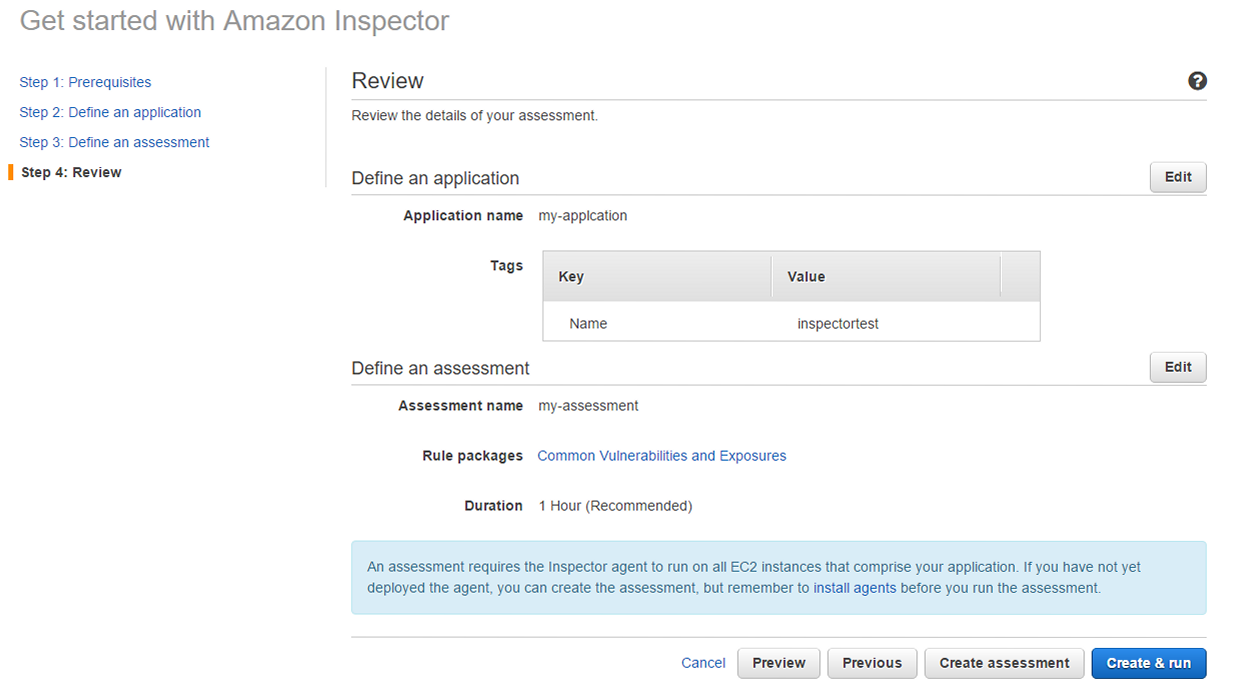
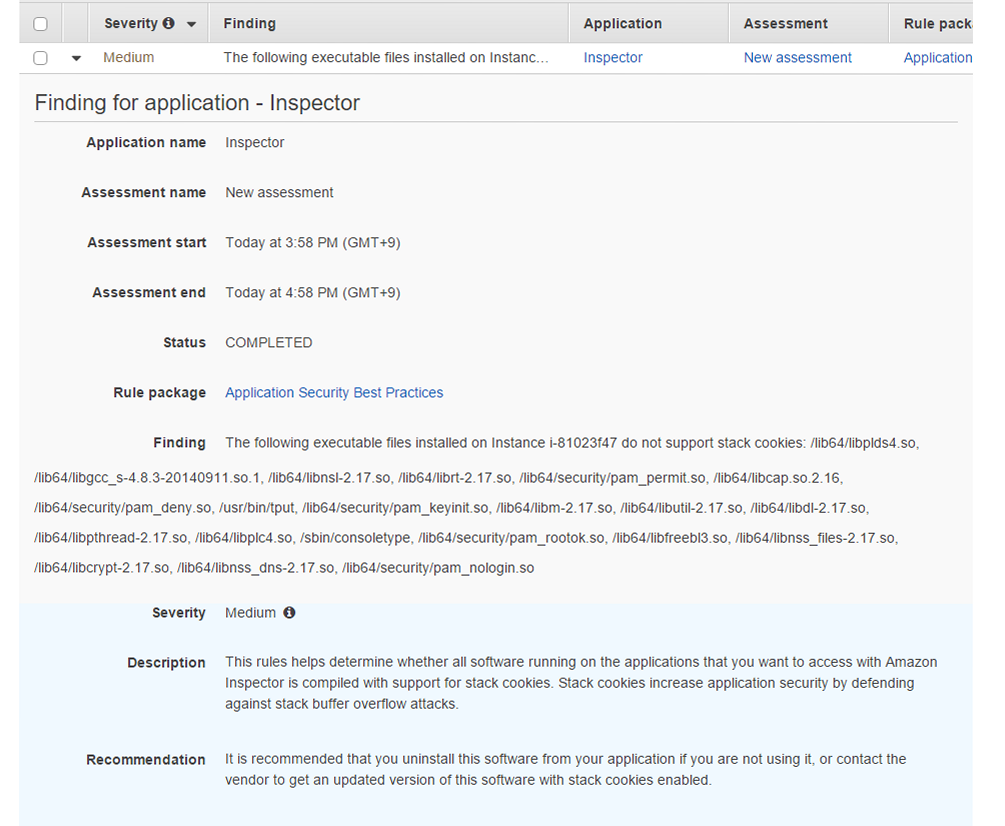
AWS IoTの設定ですが、ハンズオン時はManagement Consoleで行いましたが、CLIでもできます。以下CLIでのAWS IoTの設定になります。
Thingの登録
aws iot create-thing --thing-name bx1
登録されたThingsを確認します。1度作成したthing名を削除して再登録しても登録自体はエラーは出ませんが、list-things、Management Consoleで確認しても登録されません。
この件、先ほど確認したところ、削除したThingで再登録できるようになっていました。
aws iot list-things
aws iot describe-thing --thing-name bx1-demo --region ap-northeast-1
証明書、秘密鍵、公開鍵を作成します。証明書は後からでも取得可能ですが、秘密鍵、公開鍵は作成時しか取得できないので、保存は忘れずに。
aws iot create-keys-and-certificate --set-as-active > cert.json
cat cert.json | jq .keyPair.PublicKey -r > thing-public-key.pem
cat cert.json | jq .keyPair.PrivateKey -r > private-key.pemm
証明書上位方は下記より取得できます。
aws iot describe-certificate --certificate-id "your-certificate-id" --output text --query certificateDescription.certificatePem > cert.pem
root証明書をダウンロードしておきます。
wget https://www.symantec.com/content/en/us/enterprise/verisign/roots/VeriSign-Class%203-Public-Primary-Certification-Authority-G5.pem -O rootCA.pem
IoTポリシを作成します。
vi policy.json
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action":["iot:*"],
"Resource": ["*"]
}]
}
aws iot create-policy --policy-name awsiot-handon-policy --policy-document file://policy.json
作成したポリシは以下で確認できます。
aws iot get-policy --policy-name awsiot-handon-policy --region ap-northeast-1
先ほど作成されたポリシを証明書と紐付けます。
aws iot attach-principal-policy --principal "certificateArn" --policy-name "awsiot-handon-policy"
Thingsも証明書に紐付けます。
aws iot attach-thing-principal --thing-name "bx1-demo" --principal "certificateArn"
certificateArnには、下記で確認することができます。
aws --profile target1 iot list-thing-principals --thing-name bx1-demo --region ap-northeast-1
AWS IoTからどんなアクションを行うかRuleで設定します。
Rule設定用のjsonテンプレートから作成するのが一番いいかと思われます。下記はDynamoDBと連携する例にはなりますが、Kinesis、Firehose、S3、SQS、SNSなどとも連携が可能です。
aws iot create-topic-rule --generate-cli-skeleton
vi rule.json
{
"ruleName": "IoTHandsonRule2",
"topicRulePayload": {
"sql": "SELECT * FROM 'handson/device01'",
"description": "",
"actions": [
{
"dynamoDB": {
"tableName": "IoTHandsonRawData",
"roleArn" : "arn:aws:iam::XXXXXXXXXXXX:role/aws_iot_dynamoDB",
"hashKeyField": "sensor",
"hashKeyValue": "${topic(2)}",
"rangeKeyField": "timestamp",
"rangeKeyValue": "${timestamp()}"
}
}
],
"ruleDisabled": false
}
}
aws iot create-topic-rule --cli-input-json file://rule.json
作成したRulesを確認します。
aws --profile target1 iot list-topic-rules --region ap-northeast-1
AWS IoTのEnd Pointは下記で確認することができます。
aws target1 iot describe-endpoint --region ap-northeast-1
先日のAWSモバイル/IoTサービス徹底攻略!!IoTハンズオンの際は、AWS IoTのエンドポイントとして、data.iot.ap-northeast-1.amazonaws.comで行いましたが、nslookupで確認したところ、同じ送信先IPアドレスになっていますので、どちらを使ってもいけると思われます。
秘密鍵、公開鍵、証明書の削除は現時点では、Management Consoleから行えないので(Deactiveは可能)、削除する場合は、CLIで行う必要があります。