
https://cloud.google.com/storage/docs/public-datasets/landsat からダウンロードできるデータで、Amazon Athenaをつかって、クエリを実行してみました。
テーブル構成は以下の通りです。
CREATE EXTERNAL TABLE athena_test.landsat_data_csv ( SCENE_ID STRING, PRODUCT_ID INT, SPACECRAFT_ID STRING, SENSOR_ID STRING, DATE_ACQUIRED DATE, COLLECTION_NUMBER STRING, COLLECTION_CATEGORY STRING, SENSING_TIME timestamp , DATA_TYPE STRING, WRS_PATH INT, WRS_ROW INT, CLOUD_COVER decimal , NORTH_LAT decimal, SOUTH_LAT decimal, WEST_LON decimal, EAST_LON decimal, TOTAL_SIZE decimal, BASE_URL STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ESCAPED BY '\\' LINES TERMINATED BY '\n' LOCATION 's3://athena-test-data01/csv/';
単一のCSVでは、Partitioningでデータスキャンする容量を減らすことは不可。(Partitioningのために、S3上でフォルダが分かれてファイルが配置されていないといけないため)
Amazon Athenaの課金は、スキャンするサイズによるので、課金にもろ響きます。Athena破産の可能性も。
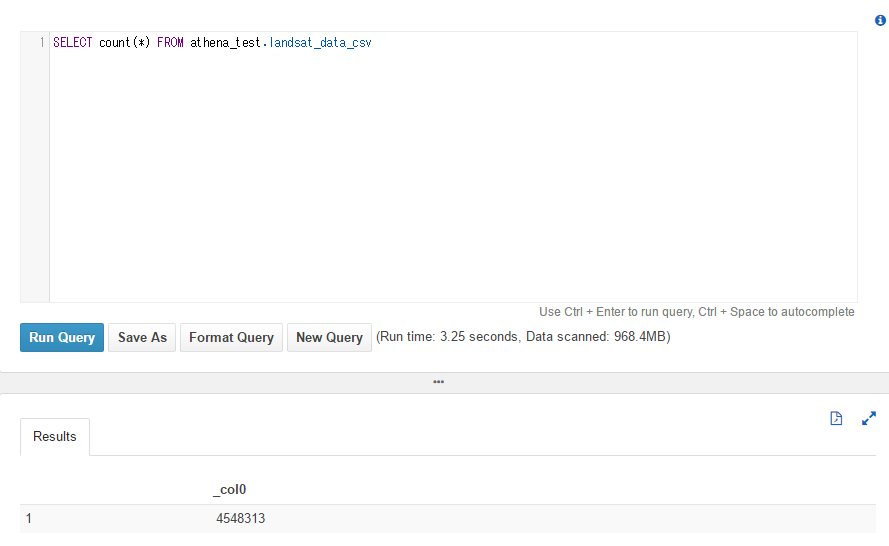
データスキャンした容量は、968MB (CSVのファイルサイズと同じなので、全スキャン)が読まれます。
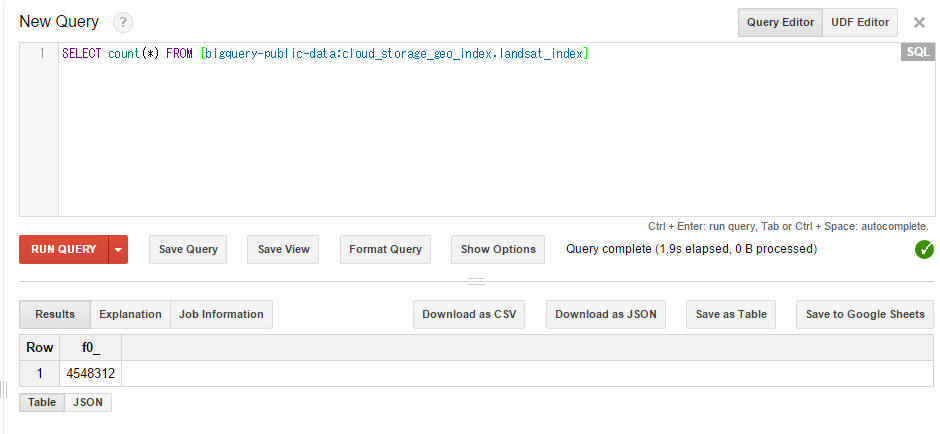
一方、同じクエリでBigQueryで実行させるとほとんどスキャンされないで結果が返る。
BigqueryのようなことがAthenaでできると思ったら、間違いです。