2025年9月23日作って学ぶFastly ComputeベースのリアルタイムアプリケーションとMCP入門 は コメントを受け付けていません
Fastly
認証をエッジでするメリットをDay1で聞いたのち、Day2で実際リアルタイムアプリケーションをfastly computeまでデプロイするまでワークショップを行いました。
ユースケース
ああYamagoya 2023 : 行動ログ収集API サーバの Fastly Compute 移行 ~ 高スケーラビリティ、高信頼性、高メンテナンス性を目指して ~
VIDEO
日経のFastly Compute移行について メンテ負荷↓、トラフィック多いところでも使っている 設定ファイルは属人化からプログラムにすることでメンテナンス負荷さげる
Yamagoya 2023 : パネルディスカッション 後編 「Climbers Talk: Fastly Compute の歩き方」
VIDEO
QRコード生成はサーバー側で動的に生成 スパイクトラフィックがくるのでFastlyで幸せになったユースケース
ワークショップ
https://gist.github.com/remore/6e23a99ff06f754b0a881bc8493db0ca
WebAssembly のファイルシステムアクセスの制限ももちろんあり
SSE(Server-Sent-Events)とイベントソース
イベント毎にリクエスト
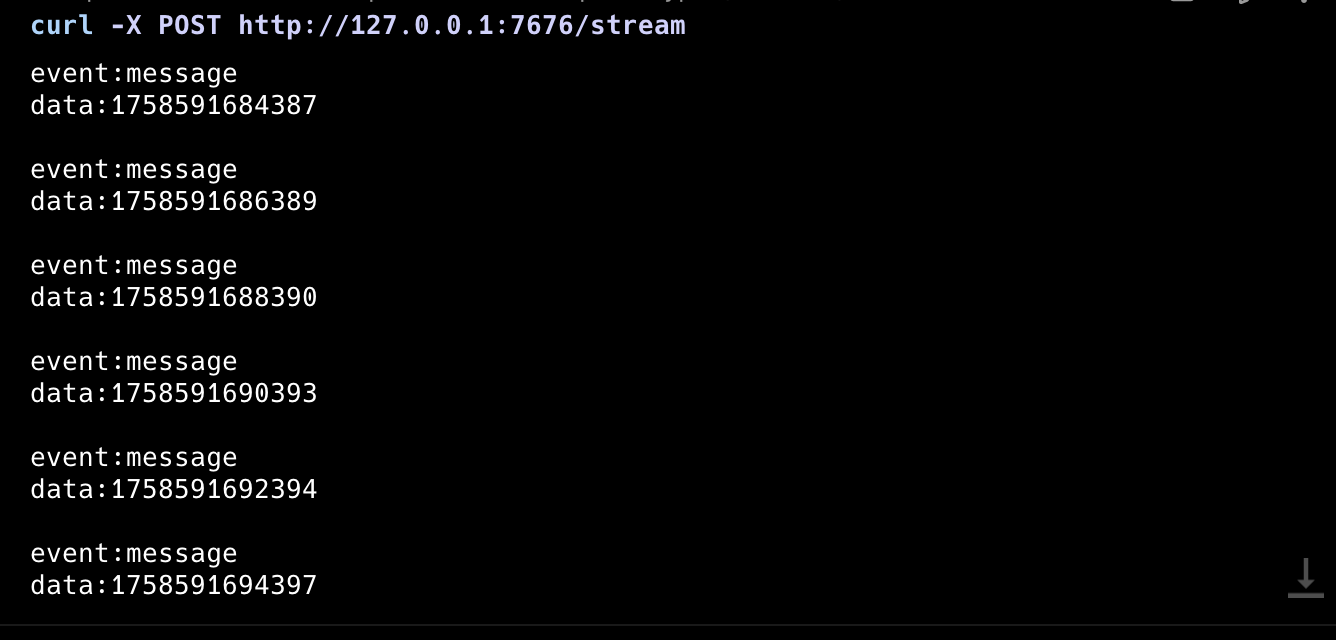
ブラウザではGETでstreamしますが、curl -X POSTをしてもリアルタイムにUTC(協定世界時)での1970年1月1日0時0分0秒から現在までの経過時間を永遠表示します。
以下は応用課題でPOSTに対応させたコード。一部Claude Codeを利用
addEventListener("fetch", event => event.respondWith(handleRequest(event)))
const htmlText = `
<html>
<body>
Latest message:<div id="main"></div>
<script>
class FetchEventSource {
constructor(url, options = {}) {
this.url = url;
this.options = options;
this.controller = null;
this.onmessage = null;
this.onerror = null;
this.onopen = null;
}
async connect() {
this.controller = new AbortController();
try {
const response = await fetch(this.url, {
method: this.options.method || 'GET',
headers: {
'Accept': 'text/event-stream',
'Cache-Control': 'no-cache',
...this.options.headers
},
body: this.options.body,
signal: this.controller.signal
});
if (!response.ok) {
throw new Error("HTTP " + response.status);
}
if (this.onopen) this.onopen();
const reader = response.body.getReader();
const decoder = new TextDecoder();
let buffer = '';
while (true) {
const { done, value } = await reader.read();
if (done) break;
buffer += decoder.decode(value, { stream: true });
const lines = buffer.split('\n');
buffer = lines.pop() || '';
let eventData = {};
for (const line of lines) {
if (line.trim() === '') {
if (eventData.data !== undefined) {
if (this.onmessage) {
this.onmessage({ data: eventData.data });
}
}
eventData = {};
} else if (line.startsWith('data:')) {
eventData.data = line.slice(5).trim();
} else if (line.startsWith('event:')) {
eventData.event = line.slice(6).trim();
}
}
}
} catch (error) {
if (error.name !== 'AbortError' && this.onerror) {
this.onerror(error);
}
}
}
close() {
if (this.controller) {
this.controller.abort();
}
}
}
const evtSource = new FetchEventSource("/stream");
evtSource.onmessage = (e) => {
document.getElementById("main").innerHTML = e.data;
};
evtSource.connect();
</script>
</body>
</html>
`;
async function handleRequest(event) {
const req = event.request;
const url = new URL(req.url);
if (url.pathname === "/stream") {
const backendResponse = await fetch("https://fastly.com");
const filteredStream = streamFilter(backendResponse.body);
return new Response(filteredStream, {
headers: new Headers({ "Content-Type": "text/event-stream" }),
});
} else {
return new Response(htmlText, {
headers: new Headers({ "Content-Type": "text/html; charset=utf-8" }),
});
}
}
function delay(ms) {
return new Promise(function (resolve, reject) {
setTimeout(resolve, ms);
});
}
const streamFilter = (inputStream) => {
const encoder = new TextEncoder();
const inputReader = inputStream.getReader();
return new ReadableStream({
async pull(controller) {
return inputReader.read().then(async ({value: chunk, done: readerDone}) => {
await delay(2000);
controller.enqueue(encoder.encode("event:message\ndata:"+Date.now()+"\n\n"));
if (readerDone) {
//controller.close();
}
});
}
});
}実行イメージ
pushpinとfanout
fanoutでリアルタイムで双方向するものを体験した。
https://www.fastly.com/documentation/guides/concepts/real-time-messaging/fanout
fanout機能はデフォルトで無効されています。このドキュメントだと30日のTrialで有効にして頂く必要あり。本日のワークショップではCustomer IDに対して有効にしてもらった。
https://www.fastly.com/documentation/guides/concepts/real-time-messaging/fanout
MCP Server
MCP Serverを立てるだけならfanoutは無効で動く。
https://www.fastly.com/blog/building-an-actually-secure-mcp-server-with-fastly-compute
Delete Serviceしたと、再度fastly compute publishした場合、fastry.tomlのservice_idを空にしないとデプロイできない
ローカルでMCP Serverのデバッグに有益なinspector
https://github.com/modelcontextprotocol/inspector
Fastly Computeにデプロイ後、Claude Codeに登録
claude mcp add test-mcp-server -- uvx "mcp-proxy" "--transport" "streamablehttp" "https://xxxxxxxxxxxxx.edgecompute.app/mcp"